海量数据实时OLAP分析系统 Druid.io安装配置与体验
随着大数据时代的到来,企业对实时OLAP(在线分析处理)系统的需求日益增长。Druid.io作为一款开源的分布式列式数据存储和查询系统,专为海量数据实时分析场景设计,具有高性能、高可用性和可扩展性的特点。本文将介绍Druid.io的基本概念、安装配置过程以及实际使用体验,帮助读者快速上手这一强大的数据处理工具。
一、Druid.io概述
Druid.io由Apache软件基金会支持,广泛应用于广告技术、物联网和监控系统等领域。其核心特性包括:
- 实时数据摄取与查询:支持从Kafka、HDFS等数据源实时摄取数据,并提供亚秒级查询响应。
- 列式存储:优化了数据压缩和查询性能,特别适合聚合分析。
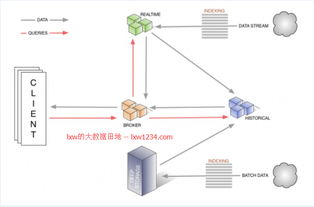
- 分布式架构:通过节点分片和复制机制确保高可用性和容错能力。
- 易于扩展:支持水平扩展,适应数据量和查询负载的增长。
二、Druid.io安装与配置
- 环境准备
- 操作系统:推荐Linux(如CentOS或Ubuntu),确保Java 8或更高版本已安装。
- 硬件要求:至少4GB内存和足够磁盘空间(根据数据规模调整)。
- 依赖组件:ZooKeeper用于协调服务,Metastore(如MySQL或PostgreSQL)用于存储元数据。
- 下载与安装
- 从Apache官网下载最新稳定版Druid.io(如版本0.22.0)。
- 解压文件到指定目录,例如:
tar -xzf apache-druid-0.22.0-bin.tar.gz。
- 进入解压目录,配置环境变量(如设置
DRUID_HOME)。
- 配置调整
- 编辑
conf/druid/cluster/_common/common.runtime.properties文件,设置ZooKeeper连接和元数据存储参数。
- 根据集群规模调整节点配置(如Coordinator、Overlord、Broker等角色)。
- 对于单机测试,可使用内置的Quickstart配置快速启动。
- 启动服务
- 运行启动脚本:
./bin/start-micro-quickstart(适用于单机环境)。
- 访问Web控制台(默认端口8888)验证服务状态。
三、体验与使用
- 数据摄取
- 通过Web界面或API导入样例数据(如JSON或CSV文件)。
- 配置数据源和摄取规范,测试实时数据流处理。
- 查询操作
- 使用Druid SQL或原生JSON查询进行数据探索。
- 执行聚合查询(如计数、求和)并观察响应速度。
- 性能评估
- 在亿级数据量下,Druid.io展现了出色的查询性能,平均响应时间在毫秒级别。
- 系统资源占用合理,扩展性测试显示线性增长趋势。
四、总结与建议
Druid.io作为实时OLAP系统的优秀代表,在数据处理服务中表现卓越。其安装配置过程相对简单,但生产环境需注意集群优化和监控。对于需要处理海量实时数据的企业,Druid.io是一个值得投入的解决方案。建议用户结合实际场景进行性能调优,并参考官方文档以获取更多高级功能。
如若转载,请注明出处:http://www.bhlmshop.com/product/2.html
更新时间:2026-06-19 10:23:47